14. Managing Pods' Computational Resources
 The Scheduler only cares about requests, not actual usage. (출처: https://livebook.manning.com/book/kubernetes-in-action/chapter-14)
The Scheduler only cares about requests, not actual usage. (출처: https://livebook.manning.com/book/kubernetes-in-action/chapter-14)
주요 내용
- Pod requests/limits 설정, 동작 방식 및 scheduling 에 미치는 영향
- Pod requests/limits 과 QoS class
- LimitRange resource, ResourceQuota object
각 pod 가 어느 정도의 자원(CPU/메모리)을 소모할지 파악하고, 이를 적절히 제한하는 것은 pod 정의에서 굉장히 중요한 부분이다.
14.1 Requesting resources for a pod’s containers
Pod 를 생성할 때 requests 와 limits 를 정할 수 있다.
- requests: 컨테이너가 필요로 하는 CPU와 메모리 양을 설정
- limits: 컨테이너가 최대로 사용할 수 있는 CPU와 메모리를 설정
이는 각 컨테이너 별로 설정할 수 있으며, pod 의 requests/limits 는 각 컨테이너들의 requests/limits 의 합이 된다.
14.1.1 Creating pods with resource requests
리소스 requests 를 가진 pod 를 생성하는 것은 무척 간단하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
apiVersion: v1
kind: Pod
metadata:
name: requests-pod
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
requests:
cpu: 200m # 200 millicore
memory: 10Mi # 메모리 10 MiB
200 millicore 라는 것은 한 CPU 코어의 1/5를 사용한다는 것이고 이는 곧 CPU 타임의 1/5 만 사용한다는 의미이다.
만약 requests 를 정하지 않으면 이 컨테이너가 자원을 임의로 할당받아도 무관하다는 뜻이 되기 때문에, 최악의 경우에는 자원을 사용하지 못하게 될 수도 있음에 유의해야 한다.
Pod 를 실행하고 top 을 쳐보면 자원을 얼마나 소비하고 있는지 확인할 수 있다.
1
2
3
4
5
6
Mem: 10819360K used, 5510064K free, 211100K shrd, 173304K buff, 5530868K cached
CPU: 4.0% usr 9.6% sys 0.0% nic 86.1% idle 0.1% io 0.0% irq 0.0% sirq
Load average: 1.21 1.08 0.79 3/2346 46
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1316 0.0 5 12.4 dd if /dev/zero of /dev/null
41 0 root R 1324 0.0 1 0.0 top
막상 확인해 보면 CPU는 12.5%를 사용하고 있는데, 이는 현재 실행 환경의 CPU 코어 수가 8개여서 그런 것이고, top 을 실행한 뒤 키보드 1 을 눌러보면 각 코어별 사용률을 볼 수 있다.
1
CPU5: 33.3% usr 66.6% sys 0.0% nic 0.0% idle 0.0% io 0.0% irq 0.0% sirq
한편 pod 정의에서는 200 millicore 로 설정했었는데, 정작 확인해보니 한 코어를 full 로 사용하고 있는 것을 확인할 수 있었다.
이처럼 requests 만 정의하는 경우에는 제한이 없으므로 컨테이너는 원하는 만큼 자원을 사용할 수 있게 된다.
14.1.2 Understanding how resource requests affect scheduling
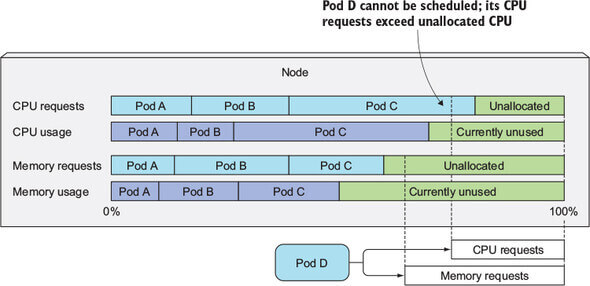
즉, requests 를 설정하게 되면 pod 가 요구하는 최소 자원을 설정하는 셈이 된다. 그렇기 때문에 이는 pod scheduling 에도 영향을 주게 된다. 최소 자원을 만족시키지 못하는 노드에 pod 를 schedule 해서는 안 되기 때문이다.
Scheduling 에서 유의할 점은 Scheduler 가 pod 를 띄울 노드를 선택할 때, scheduling 당시에 소비되고 있는 자원들의 상태를 확인하는 것이 아니라, 노드에 존재하는 pod 들의 자원 requests 총합을 확인한다는 점이다.
이렇게 해야 각 pod 의 requests 를 모두 만족시킬 수 있기 때문이다. Scheduling 당시에 자원이 적게 소모된다고 해서 괜찮다고 생각하고 scheduling 해버리면 나중에 자원이 부족해진다.
Scheduler 가 pod 의 requests 를 만족하는 노드를 찾았다면, 이제 실제로 할당을 하면 되는데, 이 때 조건에 맞는 노드가 여러 개 일수도 있다. 이 경우 우선순위를 두는 방법이 2가지 있다.
LeastRequestedPriority: 여유 자원이 많은 노드를 선호하는 방법MostRequestedPriority: 여유 자원이 적은 노드를 선호하는 방법
MostRequestedPriority의 경우 클라우드에서 사용하는 노드 수를 줄이기 위해 사용할 수 있다. 물론 여러 노드를 띄워서 각 노드가 여유롭게 작업하도록 하면 좋겠지만, 비용을 절감하기 위해 노드의 자원을 최대한 전부 사용하도록 선택하는 경우도 있다.
노드의 자원 양 확인하는 방법
kubectl describe nodes 를 하면 중간에 Capacity, Allocatable 부분이 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Capacity:
cpu: 8
ephemeral-storage: 102686648Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 16329424Ki
pods: 110
Allocatable:
cpu: 8
ephemeral-storage: 102686648Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 16329424Ki
pods: 110
참고로 Non-terminated Pods 부분을 보면 CPU Requests column 이 있는데, 직접 생성한 pod 이외에도 kube-system 과 관련된 pod 들이 실행 중이며, 이 pod 들도 requests 가 있다는 점을 기억해 두어야 한다. 시스템 pod 들이 일부 리소스를 사용 중이므로 사용자가 생성한 컨테이너 만으로 CPU 전체를 쓸 수는 없다.
14.1.3 Understanding how CPU requests affect CPU time sharing
앞에서 requests 만 설정하고 limits 를 두지 않았기 때문에 CPU 사용에 제한이 없다고 했는데, 만약 여러 개 pod 를 띄우게 되면 여분의 CPU time 은 각 pod 의 request 양의 비율에 맞게 배분된다.
예를 들어 2개의 pod 이 각각 200m, 1000m 의 CPU 를 요청했다면, 남는 CPU 는 1:5 로 비례배분되어 각 pod 이 사용하게 된다.
하지만 항상 이렇게 되는 것은 아니고, 한 pod 가 idle 상태일 때 다른 pod 에서 CPU 를 더 많이 가져가서 쓰려고 하면 사용할 수 있으며, idle 상태에서 벗어나 CPU 를 요청하게 되면 더 많이 쓰던 pod 에는 throttling 이 걸리게 된다.
14.1.4 Defining and requesting custom resources
Kubernetes 에서는 사용자 지정 resource 를 정의해서 requests 에 포함할 수 있다. (Extended Resources since version 1.8)
14.2 Limiting resources available to a container
이번에는 자원의 최대 사용량을 제한해 본다.
14.2.1 Setting a hard limit for the amount of resources a container can use
CPU는 compressible 이므로, pod 들의 사용량 총합이 100% 를 넘어가도 throttling 이 걸려서 계산이 느려지지만 돌아가기는 한다. 반면 메모리는 incompressible 이기 때문에 절대적인 양이 부족하면 할당이 되지 않고 프로세스가 실행되지 않는다.
특히 메모리의 경우 limit 을 걸지 않으면 한 pod 가 메모리를 지나치게 사용하여 다른 pod 에게 영향을 줄 수 있다. Scheduler 는 실제 사용량이 아니라 requests 만 보기 때문에 실제 사용량이 requests 보다 많을 경우 schedule 은 됐지만 pod 이 시작되지 않을 수 있다.
Limits 를 이용해서 pod 생성하기
requests 때와 유사하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
apiVersion: v1
kind: Pod
metadata:
name: limited-pod
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
limits: # 리소스 제한
cpu: 1
memory: 20Mi
참고로 requests 를 명시하지 않으면 limits 와 동일한 값으로 설정된다.
Limits 가 노드 capacity 의 100% 를 초과하는 경우
requests 의 경우 노드 allocatable 양보다 무조건 같거나 작아야 하지만, limits 의 경우 별도의 제약이 없다. 노드 capacity 의 100% 를 초과할 수 있다.
단, 이 경우 자원이 모두 사용되었기 때문에 pod/container 가 kill 될 수 있다.
14.2.2 Exceeding the limits
만약 컨테이너가 limits 값보다 더 많은 리소스를 사용하려고 하는 경우,
- CPU의 경우 throttling 이 걸리게 된다.
- 메모리의 경우
OOMKilled상태가 되고 프로세스가 kill 된다.
만약 restart policy 가 Always/OnFailure 이면 바로 재시작되기는 하는데, 또 메모리 초과로 kill 되며 이 상황이 반복적으로 나타나는 경우 restart 를 지연하게 되며 CrashLoopBackOff 상태로 들어가게 된다.
각 restart 마다 delay 를 2배씩 증가시켜 최대 300초까지 늘리며, 이후로부터는 300초마다 재시작을 시도한다.
OOMKilled 상태는 kubectl describe pod 에서 볼 수 있다.
따라서 메모리 limit 은 신중하게 설정해야 한다.
14.2.3 Understanding how apps in containers see limits
주의할 점은 컨테이너는 limit 값을 모른다는 점이다! Limit 을 설정했지만, 컨테이너 안의 프로세스가 메모리를 확인할 때 자신이 실행 중인 노드의 전체 메모리를 보게 된다.
그래서 만약 애플리케이션이 메모리를 확인하고 여유 메모리 값에 따라 메모리를 할당하게 되면 limit 과 관계없이 더 많은 양의 메모리를 할당하려고 할 수 있다.
JVM
-Xmx옵션을 사용하지 않으면 JVM 은 호스트(노드)의 메모리를 고려하여 heap size 를 잡기 때문에 프로덕션 환경에서 heap size 가 크게 잡혀OOMKilled가 발생할 수 있다.
마찬가지로 CPU 도 노드의 모든 CPU를 보게 된다. 단지 CPU limit 을 걸면 사용 시간 제한이 걸리는 것이다.
CPU도 문제가 되는 경우가 있는데, 코어 수를 참고하여 worker thread 를 생성하는 경우, CPU limit 의 제한을 받아 threading 의 효과를 전혀 못 받게 될 수도 있다.
이러한 경우 Kubernetes Downward API 를 이용해서 CPU limit 값을 애플리케이션에 넘겨주는 식으로 해결할 수 있다.
14.3 Understanding pod QoS classes
위에서 limits 의 경우 100% 를 초과할 수 있다고 했는데, 초과하면 어떤 컨테이너나 pod 를 kill 해야 한다고 했다. 어떤 pod 가 kill 되는지는 내부적으로 정해져 있다.
Kubernetes 에서는 pod 를 3개의 QoS 클래스로 나눠서 관리하고 이에 따라 kill 우선순위가 정해진다.
14.3.1 Defining the QoS class for a pod
QoS 클래스는 따로 pod 정의에 설정하는 것이 아니고, requests/limits 값으로부터 자동으로 도출된다.
QoS Class 는
kubectl describe pod에서도 확인할 수 있다.
BestEffort class
- requests/limits 가 설정되지 않은 컨테이너가 하나라도 존재하는 경우 pod 에게 부여된다.
- Pod 가 사용 가능한 리소스에 대해 어떠한 보장도 되지 않는다. Starvation 이 일어날 수도 있으며, 노드 capacity 를 초과하는 경우 먼저 kill 된다.
Guaranteed class
- 모든 컨테이너의 requests 와 limits 값이 일치하는 pod 에게 부여된다.
- CPU/메모리 모두 requests/limits 가 모든 컨테이너에 부여되어야 하며 그 값이 같아야 한다.
- 이 pod 내의 컨테이너는 request 한 만큼 자원을 받지만 limits 때문에 그 이상 받지는 못한다.
Burstable class
BestEffort, Guaranteed 가 아닌 pod 는 전부 이 클래스에 속한다.
kill 우선순위
BestEffort > Burstable > Guaranteed 순으로 kill 된다.
BestEffort가 먼저 kill 되는 이유는 requests/limits 를 explicit 하게 set 한 것에 대한 존중(?)이라고 생각할 수 있다.
14.3.2 Understanding which process gets killed when memory is low
QoS 클래스 순서대로 kill 이 일어나지만, QoS 클래스가 같은 pod 가 여러 개 있으면 어떤 pod 를 kill 할지 결정해야 한다.
이 경우 OutOfMemory (OOM) score 를 계산한다. 시스템에서는 OOM score 가 가장 높은 프로세스를 죽인다.
OOM score 의 계산에는 2가지 요인이 들어간다.
- 프로세스가 잡고 있는 메모리 중 사용 가능한 메모리의 비율
- Fixed OOM score adjustment
잡은 메모리 중 사용 비율이 높을수록 먼저 kill 된다.
14.4 Setting default requests and limits for pods per namespace
requests/limits 를 설정하지 않으면 kill 의 대상이 될 수 있으므로 설정하는 것이 좋다. 각 컨테이너에 이를 설정하는 것은 번거로우므로, Kubernetes 에서는 LimitRange 리소스를 제공한다.
14.4.1 Introducing the LimitRange resource
각 namespace 별로 자원의 최솟값/최댓값을 설정할 수 있으며, requests 를 설정하지 않은 컨테이너에게는 기본값을 제공해준다.
LimitRange 리소스는 LimitRanger Admission Control plugin 에서 사용하는데, pod 이 새롭게 생성될 때 pod manifest validation 과정에서 사용된다. 주로 지나치게 큰 자원의 생성을 막기 위해 사용한다.
또 기억할 점은 LimitRange 는 각 pod 에 적용되는 것이기 때문에 pod 전체에서 사용하는 리소스의 합을 제한하지는 않는다.
Pod 전체에서 사용하는 리소스 제한은 ResourceQuota 로 한다.
14.4.2 Creating a LimitRange object
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
apiVersion: v1
kind: LimitRange
metadata:
name: example
spec:
limits:
- type: Pod # Pod 전체에 걸리는 range
min:
cpu: 50m
memory: 5Mi
max:
cpu: 1
memory: 1Gi
- type: Container # 컨테이너에 걸리는 range
defaultRequest: # requests 기본값
cpu: 100m
memory: 10Mi
default: # limits 기본값
cpu: 200m
memory: 100Mi
min:
cpu: 50m
memory: 5Mi
max:
cpu: 1
memory: 1Gi
maxLimitRequestRatio: # limit / request (비율)의 범위
cpu: 4
memory: 10
- type: PersistentVolumeClaim # PVC 용량 제한
min:
storage: 1Gi
max:
storage: 10Gi
14.4.3 Enforcing the limits
LimitRange 리소스를 생성한 뒤 range 를 벗어난 pod 를 생성하려고 하면 reject 된다.
14.4.4 Applying default resource requests and limits
LimitRange 는 namespaced resource 이므로 한 namespace 에만 적용된다. 따라서 namespace 별로 LimitRange 를 만들어 두면 제한을 다르게 할 수 있다.
14.5 Limiting the total resources available in a namespace
LimitRange 는 pod 전체의 리소스 총합을 제한하지는 못한다. 하지만 클러스터 관리자 입장에서는 namespace 별로 리소스 총량을 제한할 필요가 있기 때문에, Kubernetes 에서는 ResourceQuota object 가 제공된다.
14.5.1 Introducing the ResourceQuota object
ResourceQuota object 를 생성해 두면, pod 이 생성되었을 때 최대 사용 가능한 자원 양을 초과하는지 ResourceQuota Admission Control plugin 이 확인한다.
ResourceQuota 에서는 CPU/메모리 뿐만 아니라 namespace 내의 각종 Kubernetes resource 의 개수를 제한할 수도 있다.
1
2
3
4
5
6
7
8
9
10
apiVersion: v1
kind: ResourceQuota
metadata:
name: cpu-and-mem
spec:
hard:
requests.cpu: 400m
requests.memory: 200Mi
limits.cpu: 600m
limits.memory: 500Mi
즉 LimitRange 는 각 pod 의 자원을 제한하지만, ResourceQuota 는 namespace 전체의 pod 자원 총합을 제한한다.
ResourceQuota 를 생성한 뒤에는 kubectl describe 로 얼마나 사용 중이고, 제한이 얼마인지 자세한 정보를 확인할 수 있다.
ResourceQuota 를 생성하게 되면 모든 pod 에 CPU/메모리 requests/limits 가 명시적으로 설정되어 있어야 한다. 이를 위해 LimitRange 를 만들어 기본값을 주도록 설정 해두는 것이 좋다.
14.5.2 Specifiying a quota for persistent storage
1
2
3
4
5
6
7
8
9
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage
spec:
hard:
requests.storage: 500Gi
ssd.storageclass.storage.k8s.io/requests.storage: 300Gi
standard.storageclass.storage.k8s.io/requests.storage: 1Ti
PVC 용량을 제한할 수도 있다. 또한 dynamic provisioning 의 경우 storage class 를 사용하는데, 각 class 마다 quota 를 제한할 수도 있다.
14.5.3 Limiting the number of objects that can be created
오브젝트 개수를 제한할 수도 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion: v1
kind: ResourceQuota
metadata:
name: objects
spec:
hard:
pods: 10
replicationcontrollers: 5
secrets: 10
configmaps: 10
persistentvolumeclaims: 5
services: 5
services.loadbalancers: 1
services.nodeports: 2
ssd.storageclass.storage.k8s.io/persistentvolumeclaims: 2
14.5.4 Specifiying quotas for specific pod states and/or QoS classes
Quota 의 경우 namespace 내의 모든 pod 에 적용됐지만, quota scope 를 이용해 적용 대상을 더욱 좁힐 수 있다. 현재 4가지의 scope 가 존재한다.
BestEffort, NotBestEffort scope 의 경우 QoS 가 BestEffort 인지 아닌지 확인하는 것이다.
Terminating, NotTerminating scope 의 경우 activeDeadlineSeconds 필드가 정의되어 있는지 아닌지에 따라 달라진다. (Pod 가 terminating 인지와는 무관하다)
activeDeadlineSeconds필드는 pod 가 terminate 되고Failed로 마킹된 이후 얼마나 더 실행해도 괜찮은지 설정하는 값이다.
Scope 를 정의한 뒤 ResourceQuota 를 만들면 해당 scope 에 해당되는 pod 만 적용된다.
1
2
3
4
5
6
7
8
9
10
apiVersion: v1
kind: ResourceQuota
metadata:
name: besteffort-notterminating-pods
spec:
scopes:
- BestEffort
- NotTerminating
hard:
pods: 4
위 ResourceQuota 의 경우 BestEffort QoS 이면서 activeDeadlineSeconds 필드가 세팅 되지 않은 pod 에만 적용된다.
BestEffort 의 경우 pod 의 개수만 제한할 수 있다. (애초에 requests/limits 가 세팅되지 않음) 나머지 3개 클래스의 경우 pod 개수 뿐만 아니라 CPU/메모리 requests/limits 모두 제한할 수 있다.
14.6 Monitoring pod resource usage
requests/limits 를 적절하게 설정하려면 pod 에서 자원이 얼마나 사용되고 있는지 확인해야 하고 이를 모니터링해야 한다.
14.6.1 Collecting and retrieving actual resource usages
Kubelet 에 cAdvisor 라는 애가 내장되어 있는데, 컨테이너와 노드의 자원 사용량을 모은다. 이를 중앙으로 모르기 위해서는 Heapster 라는 추가 컴포넌트를 실행해야 한다.
Heapster 는 현재 deprecated!
Heapster 는 Service 로 실행되어 IP 주소로 접근이 가능하고, 각 노드의 cAdvisor 로부터 정보를 모은다.
minikube 에서는
minikube addons enable metrics-server로 실행한다.
실행 후 data aggregation 을 위해 조금 기다리면 kubectl top node 커맨드를 실행하여 실제 현재의 CPU/메모리 사용량을 볼 수 있다.
1
2
3
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
minikube 2003m 25% 1128Mi 7%
kubectl top pod 를 하면 pod 의 상태도 확인할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
$ kubectl top pod --all-namespaces
NAMESPACE NAME CPU(cores) MEMORY(bytes)
bar test 0m 9Mi
default requests-pod 954m 2Mi
default requests-pod2 949m 1Mi
foo test 0m 11Mi
kube-system coredns-74ff55c5b-4f8ft 1m 11Mi
kube-system etcd-minikube 10m 98Mi
kube-system ingress-nginx-controller-65cf89dc4f-zhztv 1m 168Mi
kube-system kube-apiserver-minikube 30m 266Mi
kube-system kube-controller-manager-minikube 9m 46Mi
kube-system kube-proxy-vz9qq 0m 16Mi
kube-system kube-scheduler-minikube 1m 15Mi
kube-system metrics-server-56c4f8c9d6-94fsb 0m 10Mi
kube-system storage-provisioner 0m 9Mi
--containers옵션을 주면 각 컨테이너 별로 확인할 수 있다.
14.6.2 Storing and analyzing historical resource consumption statistics
cAdvisor 와 Heapster 는 단기간 동안만 정보를 보관하기 때문에, 장기간 분석을 위해서는 InfluxDB 와 Grafana 를 이용한다.
InfluxDB 는 시계열 데이터베이스로 애플리케이션 metric 과 모니터링 데이터를 저장하기에 좋다. Grafana 는 분석 및 시각화 툴로 브라우저에서 접근할 수 있다. 이 둘 모두 pod 으로 실행할 수 있다.
Grafana 에서는 클러스터, Pod 단위로 requests/limits 뿐만 아니라 리소스 사용량도 확인할 수 있다. 또한 긴 기간에 대해서도 확인 가능하다.