16. The GMW Protocol
There are two types of MPC protocols, generic and specific. Generic protocols can compute arbitrary functions. Garbled circuits were generic protocols, since it can be used to compute any boolean circuits. In contrast, the summation protocol is a specific protocol that can only be used to compute a specific function. Note that generic protocols are not necessarily better, since specific protocols are much more efficient.
GMW Protocol
The Goldreich-Micali-Wigderson (GMW) protocol is a designed for evaluating boolean circuits. In particular, it can be used for XOR and AND gates, which corresponds to addition and multiplication in $\Z_2$. Thus, the protocol can be generalized for evaluating arbitrary arithmetic circuits.
We assume semi-honest adversaries and static corruption. The GMW protocol is known to be secure against any number of corrupted parties. We also assume that any two parties have private channels for communication.
The idea is secret sharing, where each party shares its input with other parties. The actual input is not revealed, and after the computation, each party holds a share of the final result.
The protocol can be broken down into $3$ phases.
- Input phase: each party shares its input with the other parties.
- Evaluation phase: each party computes gate by gate, using the shared values.
- Output phase: each party publishes their output.
Input Phase
Suppose that we have $n$ parties $P_1, \dots, P_n$ with inputs $x_1, \dots, x_n \in \braces{0, 1}$. The inputs are bits but they can be generalized to inputs over $\Z_q$ where $q$ is prime.
Each party $P_i$ shares its input with other parties as follows.
- Choose random ${} r_{i, j} \la \braces{0, 1} {}$ for all $j \neq i$ and send $r_{i, j}$ to $P_j$.
- Set ${} r_{i, i} = x_i + \sum_{i \neq j} r_{i, j} {}$.
Then we see that $x_i = \sum_{j = 1}^n r_{i, j} {}$. Each party has a share of $x_i$, which is $r_{i, j}$. We have a notation for this,
\[[x_i] = (r_{i, 1}, \dots, r_{i, n}).\]It means that $r_{i, 1}, \dots, r_{i, n}$ are shares of $x_i$.
After this phase, each party $P_j$ has $n$ shares $r_{1, j}, \dots, r_{n,j}$, where each is a share of $x_i$.
Evaluation Phase
Now, each party computes each gate using the shares received from other parties. We describe how the XOR and AND gate are computed.
Evaluating XOR Gates
Suppose we want to compute a share of ${} c = a + b {}$. Then, since
\[[c] = [a] + [b],\]each party can simply add all the input shares.
If ${} {} y = x_1 + \cdots + x_n {} {}$, then party $P_j$ will compute ${} y_j = \sum_{i=1}^n r_{i, j} {}$, which is a share of $y$, $[y] = (y_1, \dots, y_n)$. It can be checked that
\[y = \sum_{j=1}^n y_j = \sum_{j=1}^n \sum_{i=1}^n r_{i, j}.\]Evaluating AND Gates
AND gates are not as simple as XOR gates. If $c = ab$,
\[c = \paren{\sum_{i=1}^n a_i} \paren{\sum_{j=1}^n b_j} = \sum_{i=1}^n a_ib_i + \sum_{1 \leq i < j \leq n} (a_ib_j + a_j b_i).\]The first term can be computed internally by each party. The problem is the second term. $P_i$ doesn’t know the values of $a_j$ and $b_j$. Therefore, we need some kind of interaction between $P_i$ and $P_j$, but no information should be revealed. We can use an OT for this.
For every pair of parties $(P_i, P_j)$, perform the following.
- $P_i$ chooses a random bit $s_{i, j}$ and computes all possible values of $a_ib_j + a_jb_i + s_{i, j}$. These values are used in the OT.
- $P_i$ and $P_j$ run a $1$-out-of-$4$ OT.
- $P_i$ keeps $s_{i, j}$ and $P_j$ receives $a_ib_j + a_jb_i + s_{i, j}$.
- If $a_ib_j + a_jb_i$ is exposed to any party, it reveals information about other party’s share.
- These are bits, so $P_i$ and $P_j$ get to keep a share of $a_ib_j + a_jb_i$. If these aren’t bits, then $s_{i, j} - a_ib_j - a_jb_i$ must be computed for inputs to the OT.
- Since $a_j, b_j \in \braces{0, 1}$, it is possible to compute all possible values, and use them in the OT. $(a_j, b_j)$ will be used as the choice of $P_j$.
Output Phase
After evaluation, each party has a share of the final output, so the share is sent to the parties that will learn the output. These shares can be summed to obtain the final output value.
Performance
Addition is easy, but multiplication gates require $n \choose 2$ OTs. Thus the protocol requires a communication round among the parties for every multiplication gate. Also, the multiplication gates on the same level can be processed in parallel.
Overall, the round complexity is $\mc{O}(d)$, where $d$ is the depth of the circuit, including only the multiplication gates.
A shallow circuit is better for GMW protocols. However, shallow circuits may end up using more gates depending on the function.
Security Proof
We show the case when there are $n-1$ corrupted parties.1 Let $P_i$ be the honest party and assume that all others are corrupted. We will construct a simulator.
Let $(x_1, \dots, x_n)$ be inputs to the function, and let $[y] = (y_1, \dots, y_n)$ be output shares. The adversary’s view contains $y$, and all $x_j$, $y_j$ values except for $x_i$ and $y_i$.
To simulate the input phase, choose random shares to be communicated, both for $P_i \ra P_j$ and $P_j \ra P_i$. The shares were chosen randomly, so they are indistinguishable to the real protocol execution.
For the evaluation phase, XOR gates can be computed internally, so we only consider AND gates.
- When $P_j$ is the receiver, choose a random bit as the value learned from the OT. Since the OT contains possible values of $a_ib_j + a_jb_i + s_{i, j}$ and they are random, the random bit is equivalent.
- When $P_j$ is the sender, choose $s_{i, j}$ randomly and compute all $4$ possible values following the protocol.
Lastly, for the output phase, the simulator has to simulate the message $y_i$ from $P_i$. Since the final output $y$ is known and $y_j$ ($j \neq i$) is known, $y_i$ can be computed from the simulator.
We see that the distribution of the values inside the simulator is identical to the view in the real protocol execution.
Beaver Triples
Beaver triple sharing is an offline optimization method for multiplication (AND) gates in the GMW protocol. Before actual computation, Beaver triples can be shared to speed up multiplication gates, reducing the running time in the online phase. Note that the overall complexity is the same.
Definition. A Beaver triple is a triple $(x, y, z)$ such that $z = xy$.
Beaver Triple Sharing
When Beaver triples are shared, $[x] = (x_1, x_2)$ and $[y] = (y_1, y_2)$ are chosen so that
\[\tag{$\ast$} z = z_1 + z _2 = (x_1 + x_2)(y_1 + y_2) = x_1y_1 + x_1y_2 + x_2y_1 + x_2y_2.\]
- Each party $P_i$ chooses random bits $x_i, y_i$. Now they must generate $z_1, z_2$ so that the values satisfy equation $(\ast)$ above.
- $P_1$ chooses a random bit $s$ and computes all $4$ possible values of $s + x_1y_2 + x_2y_1$.
- $P_1$ and $P_2$ run a $1$-out-of-$4$ OT.
- $P_1$ keeps $z_1 = s + x_1y_1$, $P_2$ keeps $z_2 = (s + x_1y_2 + x_2y_1) + x_2y_2$.
Indeed, $z_1, z_2$ are shares of $z$.2 See also Exercise 23.5.3
Evaluating AND Gates with Beaver Triples
Now, in the actual computation of AND gates, proceed as follows.
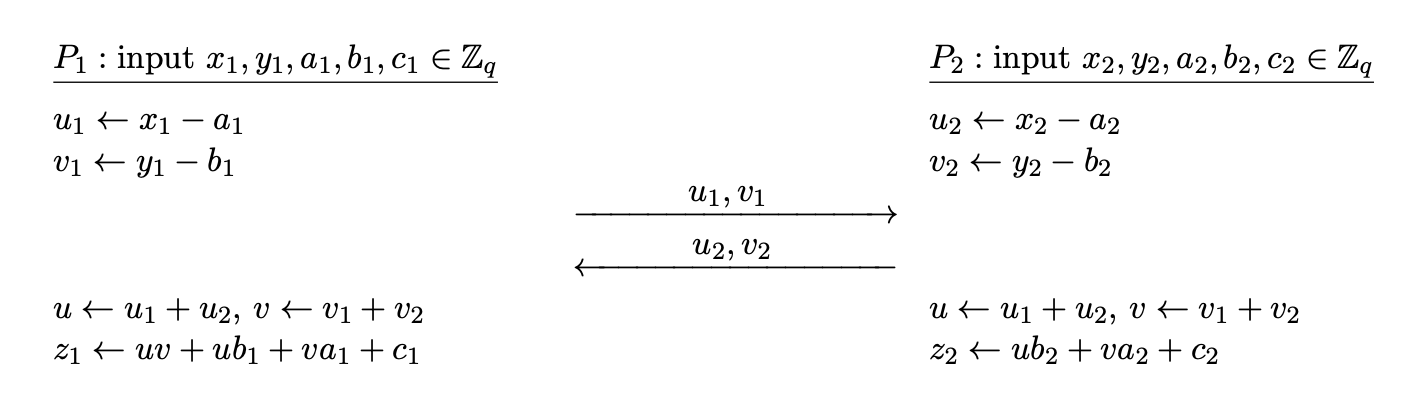
Each $P_i$ has a share of inputs $a_i, b_i$ and a Beaver triple $(x_i, y_i, z_i)$.
- Each $P_i$ computes $u_i = a_i + x_i$, $v_i = b_i + y_i$.
- $P_i$ shares $u_i, v_i$ to $P_{3-i}$ and receives $u_{3-i}, v_{3-i}$ from $P_{3-i}$.
- Each party now can compute $u = u_1 + u_2$, $v = v_1 + v_2$.
- $P_1$ computes $c_1 = uv + uy_1 + vx_1 + z_1$, $P_2$ computes $c_2 = uy_2 + vx_2 + z_2$.
Note that
\[\begin{aligned} c = c_1 + c_2 &= uv + u(y_1 + y_2) + v(x_1 + x_2) + (z_1 + z_2) \\ &= uv + uy + vx + xy \qquad (\because z = xy) \\ &= u(v + y) + x(v + y) \\ &= (u + x)(v + y) = ab \end{aligned}\]The last equality comes from the fact that $u = a + x$ and $v = b+y$ from step $1$. The equation was derived from the following observation.
\[c = ab = (a + x)(b + y) - x(b + y) - y(a + x) + xy.\]Substitute $u = a +x$ and $v = b + y$, since $z = xy$, we have
\[c = uv - xv - yu + z.\]Thus
\[[c] = uv - [x]v - [y]u + [z],\]and $uv$ is public, so any party can include it in its share.
Also note that $u_i, v_i$ does not reveal any information about $x_i, y_i$. Essentially, they are one-time pad encryptions of $x_i$ and ${} y_i {}$ since $a_i, b_i$ were chosen randomly. No need for OTs during actual computation.
Reusing Beaver Triples?
Beaver triples are to be used only once! If $u_1 = a_1 + x_1$ and ${} u_1’ = a_1’ + x_1 {}$, then $u_1 + u_1’ = a_1 + a_1’$, revealing information about $a_1 + a_1’$.
Thus, before the online phase, a huge amount of Beaver triples are shared to speed up the computation. This can be done efficiently using OT extension described below.
Comparison of Yao and GMW
| Protocol | Yao | GMW |
|---|---|---|
| Metaphor | Apple: bite-by-bite | Orange: peel and eat |
| Pros | Constant round complexity | Circuit evaluation is simple |
| Cons | Requires symmetric cipher in the online phase | High overhead in AND gates |
| Good In | High latency networks | Low latency networks |
| Round Complexity | $\mc{O}(1)$ | Depends on circuit depth. $n$ OTs per AND gates per party. |
Yao’s protocol computes gates bite-by-bite, whereas GMW protocol is peel-and-eat. Most of the effort is required in the preprocessing phase, by sharing many Beaver triples, but the evaluation phase is easy.
OT Extension
Both Yao’s and GMW protocol use OTs. Depending on the computation, one may end up performing thousands of OTs, which can be inefficient.
There is a technique called OT extension, that allows us to obtain many OT instances from a small number of OT instances. OT extension only uses small number of base OTs, and uses symmetric cipher to extend it to many OTs.
Protocol Description
This protocol will extend $n$ OTs to $m$ OTs, where $m \gg n$.
- Sender has inputs $\paren{x_i^0, x_i^1}$ for $i = 1, \dots, m$.
- Receiver has choice vector $\sigma = (\sigma_1, \dots, \sigma_m) \in \braces{0, 1}^m$.
- After the protocol, the receiver will get $x_i^{\sigma_i}$ for $i = 1, \dots, m$.
First phase.
- The receiver samples $n$ random strings $T_1, \dots, T_n \la \braces{0, 1}^m$ of length $m$.
- The receiver prepares pairs $\paren{T_i, T_i \oplus \sigma}$ for $i = 1, \dots, n$ and plays sender in base OT.
- The sender chooses random $s = (s_1, \dots, s_n) \in \braces{0, 1}^n$.
- The sender plays receiver in base OT with input $s_i$ for $i = 1, \dots, n$.
In the first phase, the roles are temporarily switched.
- The receiver chose $n$ random $m$-bit vectors, now has a $m\times n$ bit matrix $T$.
- For the $i$-th base OT, the receiver inputs $T_i$ or $T_i \oplus \sigma$. Therefore, if $s_i = 0$, the sender gets $T_i$. If $s_i = 1$, then sender gets $T_i \oplus \sigma$.
- Suppose that the sender gets $Q_i \in \braces{0, 1}^m$ in the $i$-th base OT. The sender will also have a $m \times n$ bit matrix $Q$.
Now consider each row separately! Let ${} A[k]$ be the $k$-th row of matrix $A$.
If $\sigma_j = 0$, the XOR operation in $T_i \oplus \sigma$ has no effect on the $j$-th element (row), so the $j$-th element of $T_i \oplus \sigma$ and $T_i$ are the same. Thus, we have $Q[j] = T[j]$.
On the other hand, suppose that $\sigma_j = 1$ and consider each element of $Q[j]$. The $i$-th element is the $j$-th element of $Q_i$. If $s_i = 0$, then $Q_i = T_i$, so the $j$-th element (row) is the same as the $j$-th element of $T_i$. If $s_i = 1$, then $Q_i = T_i \oplus \sigma$, so the $j$-th element is flipped. Thus, $Q[j] = T[j] \oplus s$.
\[Q[j] = \begin{cases} T[j] & (\sigma_j = 0) \\ T[j] \oplus s & (\sigma_j = 1). \end{cases}\]Second phase. To perform the $j$-th transfer $(j = 1, \dots, m)$,
- The sender sends $y_j^0 = H(j, Q[j]) \oplus x_j^0$ and $y_j^1 = H(j, Q[j] \oplus s) \oplus x_j^1$.
- The receiver computes $H(j, T[j]) \oplus y_j^{\sigma_j}$.
If $\sigma_j = 0$, then the sender gets
\[H(j, T[j]) \oplus y_j^0 = H(j, T[j]) \oplus H(j, Q[j]) \oplus x_j^0 = x_j^0.\]If $\sigma_j = 1$,
\[H(j, T[j]) \oplus y_j^1 = H(j, T[j]) \oplus H(j, Q[j] \oplus s) \oplus x_j^1 = x_j^1.\]We have just shown correctness.
Security Proof of OT Extension
Intuitively, the sender receives either $T_i$ or $T_i \oplus \sigma$. But $T_i$ are chosen randomly, so it hides $\sigma$, revealing no information.
As for the receiver, the values $(x_j^0, x_j^1)$ are masked by a hash function, namely $H(j, Q[j])$ and $H(j, Q[j] \oplus s)$. The receiver can compute $H(j, T[j])$, which equals only one of them but since receiver has no information about $s$, prohibiting the receiver from computing the other mask.
Performance of OT Extension
The extension technique allows us to run $n$ base OT instances to obtain $m$ OT instances. For each of the $m$ OT transfers, only a few hash operations are required, resulting in very efficient OT.
One may concern that we have to send a lot of information for each of the $n$ OT instances, since we have to send $m$ bit data for each OT. But this of not much concern. For example, if we used OT based on ElGamal, we can choose primes large enough $> 2^m$ to handle $m$-bit data.
Hence, with OT extensions, we can perform millions of OTs efficiently, which can be used especially for computing many Beaver triples during preprocessing.
Intuitively, it may seem that proving security for $n-1$ corrupted parties would be the hardest. However, security for $n-1$ corrupted parties does not imply security for $n-2$ corrupted parties, in general. ↩︎
There is a variant of sharing Beaver triples, where a dealer generates all $x_i, y_i, z_i$ and gives them to each party. ↩︎
A Graduate Course in Applied Cryptography. ↩︎